Xiang (Ivy) LiHow I Mastered the ‘Databricks Certified Associate Developer for Apache Spark 3.0’If you know nothing about Spark but are interested in it, this article will take you from a beginner to a Spark master, step by stepFeb 3Feb 3
InDev GeniusbyPrem Vishnoi(cloudvala)Top 10 Spark Tuning Techniques for Efficient Data ProcessingMaster Spark performance optimization with these very important tuning or optimisation techniques.Aug 25, 20241Aug 25, 20241
InTowards DevbyAvin KohaleNuances of Data Engineering ft. Spark and DatabricksMy collection of bad interview experiences wrapped up in a blog🥲Jan 231Jan 231
Avin KohaleSpark — Beyond basics: Required Spark memory to process 100GB fileProcessing 100GBs file is a cake walk for spark ONLY if you know how to assign spark memory efficiently! Read to know more.Aug 1, 202411Aug 1, 202411
Jai SinghConfiguring Executors, Cores, and Memory for Spark : A Practical Visualisation GuideSetting up a Spark application on YARN can be tricky — especially when it comes to deciding on the right numbers for executors, cores, and…Nov 6, 20241Nov 6, 20241
InSelectFrombyWasurat SoontronchaiSpark Performance Tuning: SpillWhat happens when data is overload your memory in Spark?Mar 19, 20222Mar 19, 20222
Archana GoyalSpark Interview Guide: Must-Know Multiple-Choice Questions with AnswersMy articles are open to everyone; non-member readers can read the full article by clicking this link.Sep 1, 2024Sep 1, 2024
Archana GoyalAdaptive Query Execution (AQE) in Apache Spark 4.0 : Revolutionizing Query OptimizationAs big data processing advances, the demand for smarter and more efficient query optimization has never been greater.Aug 25, 20243Aug 25, 20243
Naveen KumarTuning Spark Optimization: A Guide to Efficiently Processing 1 TB DataThe aim of this article is to provide a practical guide on how to tune Spark for optimal performance, focusing on partitioning strategy…Oct 3, 20242Oct 3, 20242
Anand SatheeshApache Spark Commonly seen errors in production and their solutions.Apache Spark is a powerful tool for big data processing, it uses distributed data processing in memory to reduce the execution time…Jul 1, 2024Jul 1, 2024
InGoogle Cloud - CommunitybyNathan BramiImplementing Incremental Strategies with DataformOverview and Prerequisites:Oct 16, 20241Oct 16, 20241
InData Engineer ThingsbyVu TrinhI spent 6 hours learning how Apache Spark plans the execution for us.Catalyst, Adaptive Query Execution, and how Airbnb leverages Spark 3.Sep 11, 20241Sep 11, 20241
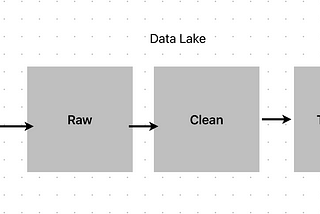
Siva IlangoPrinciples of Data layers in Data PlatformData organizing principles are vital when we build the data platform to enable data maturity for the business.Sep 9, 20232Sep 9, 20232
Oindrila ChakrabortyDifferent Types of “Join Strategies” in “Apache Spark”What is “Join Selection Strategy”?Oct 6, 20235Oct 6, 20235
Vishal BarvaliyaHow Many Partitions Will Be Created for a 10 GB File?Access this blog for free…Aug 18, 20243Aug 18, 20243
Ankush SinghWhat: All About Bucketing and Partitioning in SparkSpark is an open-source distributed computing system that has gained significant traction in the big data space for its ability to handle…Jun 13, 20232Jun 13, 20232
InData Engineer ThingsbyVu TrinhHow does Uber handle petabytes of Spark shuffle data every day?The Remote External Service (RSS)Jun 22, 20241Jun 22, 20241
InGoogle Cloud - CommunitybyVishal BulbuleRestore deleted data from BigQuery using time travel feature🚀⏰✨IntroductionJul 10, 20232Jul 10, 20232
Suffyan AsadHandling Data Skew in Apache Spark: Techniques, Tips and Tricks to Improve PerformanceDiscover how to detect and mitigate data-skew in Spark. Learn about the impact of data-skew and how to detect and fix it!Jan 30, 20234Jan 30, 20234